Modern Data Stack Architecture - Cost-Effective Cloud Infrastructure for $10/Month
Objective:
Design and implement a modern data stack that delivers scalable, efficient, and secure data processing and analytics capabilities, with a total operational cost capped at $10 per month. This system will leverage cloud-native tools, serverless architecture, and open-source technologies to optimize data ingestion, storage, transformation, and visualization. The solution will ensure data quality, pipeline automation, and integration with low-cost analytics platforms while maintaining high availability and performance for small to medium-scale use cases.
Key Features of My Data Stack:
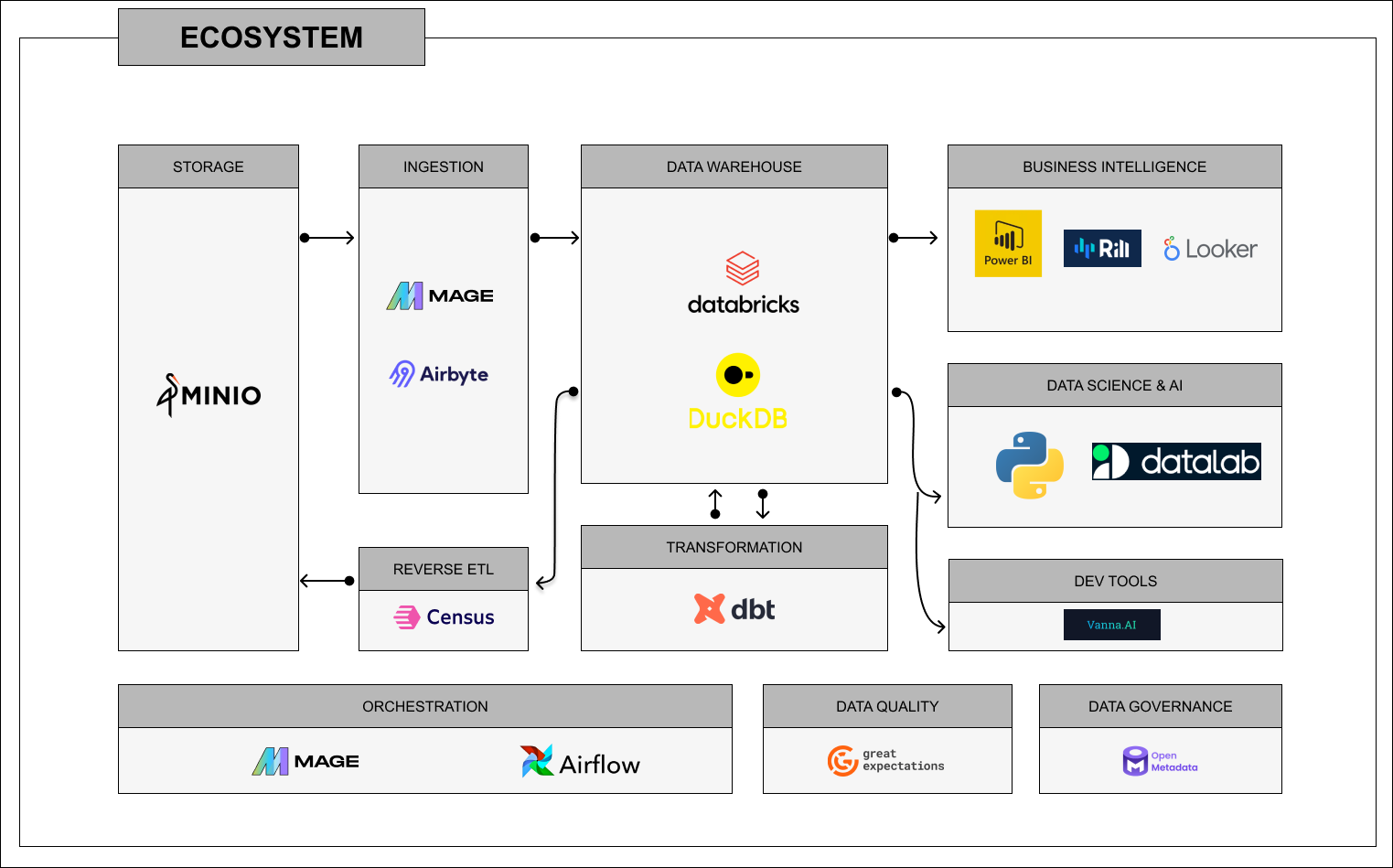
I’ve designed this modern data stack to be flexible, allowing me to quickly change or upgrade components to stay aligned with evolving technologies. It covers all aspects from storage, ingestion, and transformation to data science, AI, and business intelligence, with a focus on automation, data quality, and governance.
- Storage: Minio provides me with scalable, S3-compatible storage.
- Ingestion: Mage and Airbyte make it easy for me to connect to various data sources with minimal configuration.
- Data Warehousing: I use DuckDB and Databricks for flexible, scalable data warehousing options that fit my needs.
- Reverse ETL: Census helps me operationalize my data by pushing insights back into my business tools.
- Transformation: dbt handles the heavy lifting of transforming and modeling my data.
- Business Intelligence: Power BI and Rill are my go-to tools for visualizing data and driving insights.
- Data Science and AI: I leverage Python and Datalab for data science and AI experiments.
- Orchestration: Mage and Airflow automate the orchestration of my data workflows.
- Data Quality: Great Expectations ensures the data I work with is accurate and reliable.
- Data Governance: OpenMetadata helps me maintain transparency and control over my data with solid governance practices.
Technology I Use in My Data Stack:
- Storage: Minio
- Ingestion: Mage, Airbyte
- Data Warehousing: DuckDB, Databricks
- Reverse ETL: Census
- Transformation: dbt
- Business Intelligence: Power BI, Rill
- Data Science & AI: Python, Datalab
- Orchestration: Mage, Airflow
- Data Quality: Great Expectations
- Data Governance: OpenMetadata
Outcome:
This stack enables me to stay ahead by allowing for rapid changes, ensuring that my system is always up-to-date with modern technology trends. It’s perfectly tailored for my personal projects, where I can experiment with new tools and features. I can easily scale and integrate my data workflows while ensuring data quality and governance. It allows me to make data-driven decisions, run AI models, and operationalize insights without being locked into outdated technologies. This flexibility and adaptability help me stay productive and innovative while keeping costs manageable.
Interested in similar projects?
I help companies build modern data solutions and web applications. Let's discuss your next project!
Contact Me