Establishing a Unified Data Ecosystem to Drive Business Insights
Project Objective:
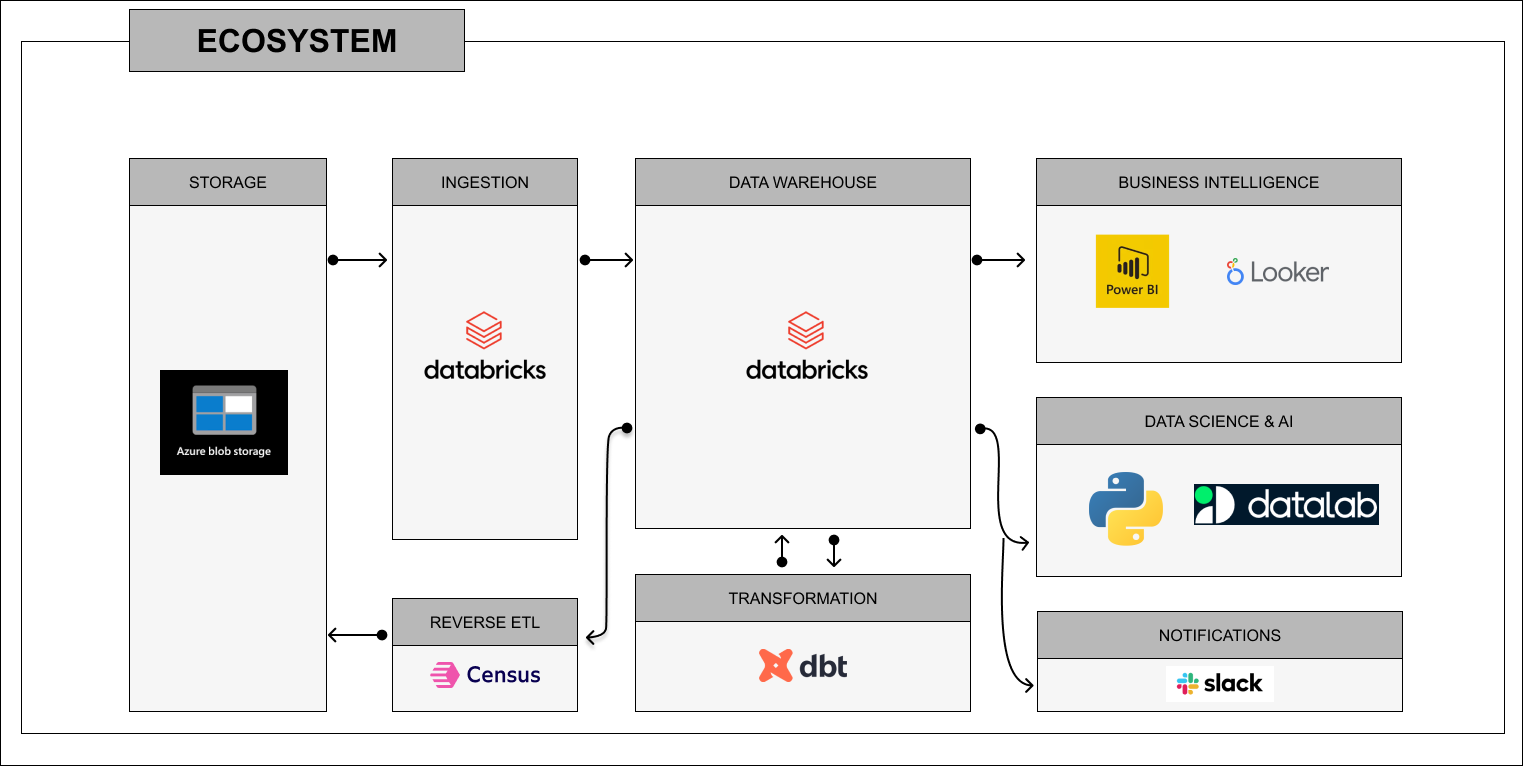
The project began with a straightforward goal: to create a centralized data lake capable of consolidating data from various systems, transforming it into a structured format, and providing an overview of available datasets. From this foundation, the aim was to enable actionable insights and fast analysis to empower business teams with real-time decision-making capabilities.
How It Started:
Initially, the project focused on solving two critical challenges:
- Bringing together data scattered across legacy databases, APIs, and file-based systems.
- Establishing a flexible architecture that could scale with growing enterprise demands.
Using established cloud technologies like Azure Blob Storage and Databricks, the team laid the groundwork for a modern, integrated data ecosystem. The emphasis was on ensuring data quality, transparency, and the ability to deliver meaningful insights.
What Was Built:
Over the course of the project, the ecosystem evolved into a full-fledged framework for modern data operations. Key components include:
- Data Storage: Azure Blob Storage serves as the backbone for the data lake, structured into raw, processed, and curated zones for seamless management.
- Data Ingestion: Azure Data Factory orchestrates the ingestion process, connecting to APIs, databases, and file-based systems for automated and incremental data loads.
- Data Transformation: Databricks, combined with PySpark and Delta Lake, powers the transformation layer, ensuring high-performance processing and schema enforcement.
- Data Quality and Governance: Great Expectations validates data consistency, while OpenMetadata provides a comprehensive view of data lineage and governance.
- Visualization and Insights: Power BI dashboards deliver interactive reporting for business users, while Python libraries like Matplotlib and Plotly support custom visualizations for data science teams.
How It Works Today:
-
Centralized Data Lake:
- All enterprise data flows into Azure Blob Storage, organized for efficient access and processing.
- Delta Lake ensures transaction support and version control for robust data handling.
-
Automated Ingestion and Transformation:
- Pipelines built in Azure Data Factory and Databricks handle data extraction, cleaning, and enrichment.
- dbt enables modular transformations, creating reusable and maintainable datasets.
-
Insights for Business Teams:
- Power BI provides dynamic dashboards for monitoring KPIs and trends in real time.
- Python visualizations offer deeper analytical capabilities for advanced use cases.
-
Data Quality and Governance:
- Automated checks flag anomalies, ensuring that only accurate, reliable data is used.
- Metadata tracking simplifies data discovery and promotes transparency across teams.
Outcome:
The project has now matured into a production-grade ecosystem that drives measurable business value. Key outcomes include:
- Enhanced Efficiency: Automated processes significantly reduce the time and effort required for data preparation.
- Rapid Decision-Making: Real-time insights empower teams to respond quickly to emerging trends.
- Scalable Architecture: The system supports growing data volumes and diverse use cases without compromising performance.
- Improved Trust in Data: Governance and quality frameworks ensure reliable, actionable insights.
Reflections:
What began as a project to consolidate and transform data has grown into a cornerstone of the enterprise’s data strategy. This ecosystem is not just a tool but a transformative solution that continues to evolve, supporting advanced analytics, machine learning, and a data-driven culture across the organization.
With this foundation in place, the focus now shifts to continuous optimization, integrating new technologies, and unlocking even greater business potential.